ImageC can be used to train simple AI models. These models can then be used for pixel classification in your pipelines.
In the actual version of ImageC two types of models are available: Random Forest Trees and Artificial Neuronal Network Multi Layer Perceptron (ANN MLP). In general it is recommended to use ANN MLP, since using deep learning networks is the more modern approach and is much more optimized in terms of execution time.
However, the process of training a model is always the same, regardless of which model type is used. Both Random Forest and MLP models are trained using supervised learning. Accordingly, labeled input data must be supplied so the models can compute the model weights during the training process.
Create training data
First of all select the Image directory in the Project tab where your images are stored in.
Select one representative image from your images.
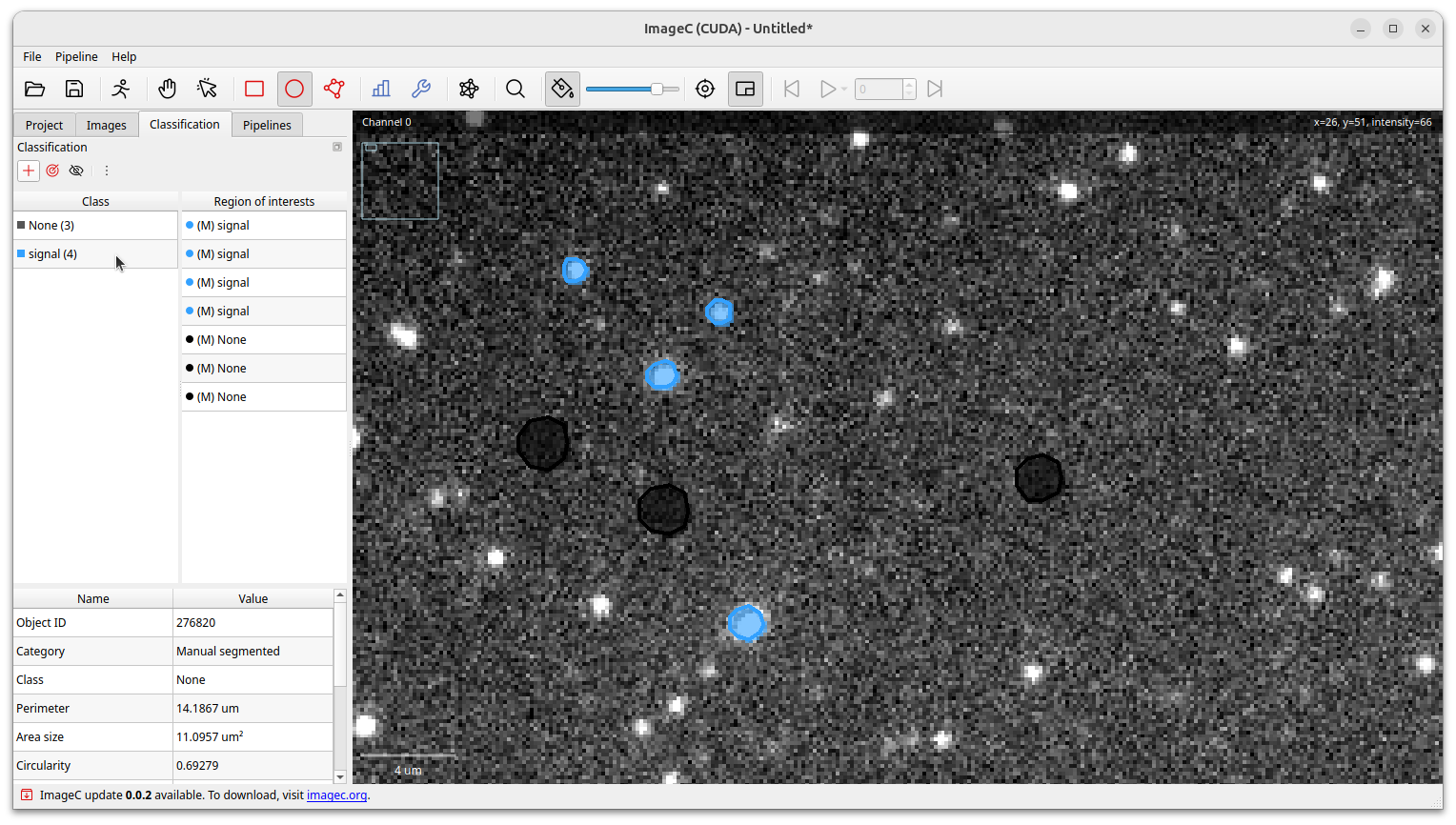
Once the image has been opened in ImageC, the labelling tools can be used to mark the areas of the image showing signal and those that do not.
Then, switch to the Classification tab and add as many classes as you need to differentiate between them.
In this simple example we just distinguish between signal and no signal.
Select the None class and mark a couple of representative areas in the image where no signal is shown.
Then select the Signal class and mark areas in the images showing a signal.
Tip Use the shortcut
Escto switch to the "Move tool", useSto switch to the "Select tool", useRto draw a rectangle,Oto draw a oval andPto draw a polygon.
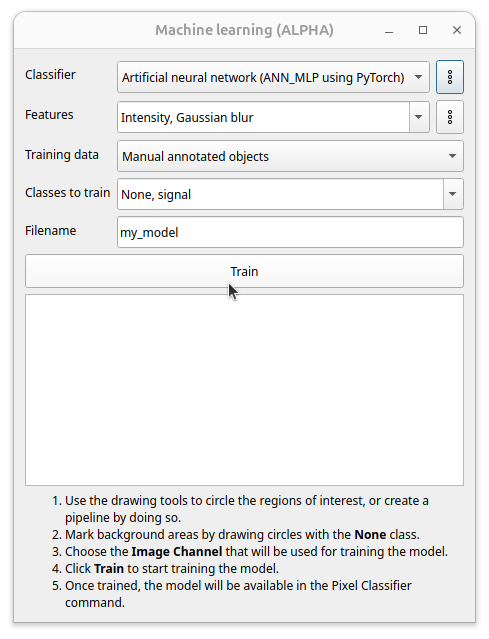
After finished the labeling open the Machine Learning dialog by clicking on the button in the toolbar. Choose the wanted classifier (model type), the features to train and which classes to use for training.
Press the Train button to start the training.
All trained models are stored in the project directory in the folder imagec/models.
Features
For effective AI model training, the original input data and the corresponding areas of interest must be provided. A simple approach is to use the unaltered original image for training. This can, however, reduce the model’s robustness, potentially causing inaccuracies when applied to images that exhibit slight deviations from the training data. Enhancing model robustness typically involves augmenting the training data by presenting the image in several variations.
By selecting several features from the feature list, you generate different variations of the original image. Each feature corresponds to a small preprocessing pipeline that is applied to the image before training. Presenting the model with all these feature-based variations during training helps it become more robust and better able to handle new data.
Tip Adding more features increases training time and execution time. So choose the features based on your application as many as needed as less as possible.
Feature variation
Open the feature variation menu using the three dots button beside the feature combobox. Using the feature variation allows to select different filter kernels which should be used in the image processing pipeline. Based on the object size to detect reducing or increasing the kernel size can improve the detection quality.
Training data
ImageC allows to use manual annotated training data or training data generated from a formal pipeline. Using trining data from a formal pipeline can increase the speed of training data generation in case of complex scenarios.
For automatic training data generation, create a pipeline which extracts your region of interests as good as possible. Edit the training data by removing wrong detected areas or/and adding not detected areas.
Now use the ML trainer with the option Pipeline annotated objects to use the labels from the pipeline for training.
Also a hybrid approach is possible by using the Any annotated objects option, which uses manuel and pipeline generated labels.